88-165 תשעב סמסטר ב/תקצירי הרצאות
תקצירי הרצאות
תוכן עניינים
- 1 הרצאה ראשונה
- 2 הרצאה שניה
- 3 הרצאה שלישית
- 4 הרצאה רביעית
- 5 הרצאה חמישית
- 6 הרצאה שישית
- 7 הרצאה שביעית
- 8 הרצאה שמינית
- 9 הרצאה תשיעית
- 10 הרצאה עשירית
- 11 הרצאה אחת-עשרה
- 12 הרצאה שתים-עשרה
- 13 הרצאה שלוש-עשרה
- 14 הרצאה ארבע-עשרה
- 15 הרצאה חמש-עשרה
- 16 הרצאה שש-עשרה
- 17 הרצאה שבע-עשרה
- 18 הרצאה שמונה-עשרה
- 19 הרצאה תשע-עשרה
- 20 הרצאה עשרים
- 21 הרצאה עשרים ואחת
- 22 הרצאה עשרים ושתיים
- 23 הרצאה עשרים ושלוש
- 24 הרצאה עשרים וארבע
- 25 הרצאה עשרים וחמש
הרצאה ראשונה
(פרק 1, סעיף 1.2).
כל נתון סטטיסטי משמעותי אפשר לתאר על-ידי משתנים סטטיסטיים. נגענו קלות בטיפוסים של משתנים (משתנה איכותי, שבו אפשר רק לתאר את ההתפלגות; משתנה אורדינלי, שבו יש משמעות לסדר אבל לא לערך המספרי; משתנה אינטרוולי שבו יש משמעות גם להפרש המספרי, ומשתנה מנתי שבו יש בנוסף גם משמעות ליחס בין ערכים). דיברנו על הצגה גרפית של נתונים והנטיה הלא מוסברת של עורכי עיתונים להטעות באמצעותה.
למדנו כמה מדדי מרכז: ממוצע, שכיח, חציון, אמצע הטווח; וכמה מדדי פיזור: סטיית התקן, הטווח, הטווח הבין-רבעוני.
לצורך השוואה בין שני משתנים הצגנו את מקדם המתאם, שערכו תמיד בין 1 ל- 1-. כשהמשתנים בלתי תלויים, מקדם המתאם שלהם קרוב לאפס ("קרוב" ולא "שווה" משום שמדובר במדגם אקראי ולא באוכלוסיה כולה).
הרצאה שניה
(סעיף 1.3 - קומבינטוריקה).
מספר הדרכים לסדר n עצמים שונים בשורה הוא 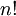 . מספר תת-הקבוצות של קבוצה בגודל n הוא
. מספר תת-הקבוצות של קבוצה בגודל n הוא 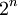 . מספר תת-הקבוצות בגודל k של קבוצה בגודל n הוא המקדם הבינומי n-מעל-k. זהו מספר הדרכים לבחור בלי החזרה, כשאין חשיבות לסדר. את המקדם הבינומי אפשר להכליל ל"מקדם מולטינומי", הסופר כמה דרכים יש לפרק קבוצה בגודל n לתת-קבוצות בגדלים
. מספר תת-הקבוצות בגודל k של קבוצה בגודל n הוא המקדם הבינומי n-מעל-k. זהו מספר הדרכים לבחור בלי החזרה, כשאין חשיבות לסדר. את המקדם הבינומי אפשר להכליל ל"מקדם מולטינומי", הסופר כמה דרכים יש לפרק קבוצה בגודל n לתת-קבוצות בגדלים 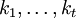 , כאשר סכום הגדלים שווה ל-n.
, כאשר סכום הגדלים שווה ל-n.
כשיש חשיבות לסדר, מספר הדרכים לבחור k עצמים עם החזרה, מתוך n, הוא החזקה 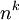 . מספר הדרכים לבחור בלי החזרה הוא
. מספר הדרכים לבחור בלי החזרה הוא 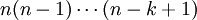 (מה קורה אם k>n?). מספר הדרכים לבחור k עצמים מתוך n, עם החזרה, כשאין חשיבות לסדר, שווה למספר הפתרונות החיוביים למשוואה
(מה קורה אם k>n?). מספר הדרכים לבחור k עצמים מתוך n, עם החזרה, כשאין חשיבות לסדר, שווה למספר הפתרונות החיוביים למשוואה 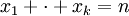 , שהוא המקדם הבינומי n+k-1 מעל n (זהו למעשה מספר ההתפלגויות האפשריות, עם x_i עצמים מסוג i).
, שהוא המקדם הבינומי n+k-1 מעל n (זהו למעשה מספר ההתפלגויות האפשריות, עם x_i עצמים מסוג i).
למדנו (והוכחנו) את עקרון ההכלה וההדחה, 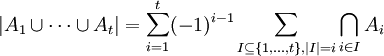 .
.
הרצאה שלישית
(סעיף 2.1 - מרחבי הסתברות בדידים)
הגדרנו: מרחב הסתברות הוא זוג סדור, הכולל את קבוצת המצבים (שהיא סופית או בת-מניה), ופונקציה מהקבוצה הזו למספרים הממשיים שסכום כל ערכיה הוא 1. תת-קבוצות של מרחב ההסתברות נקראות "מאורעות". את הפונקציה  אפשר להמשיך לפונקציה
אפשר להמשיך לפונקציה 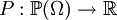 , המוגדרת על כל המאורעות. לערך
, המוגדרת על כל המאורעות. לערך 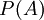 קוראים "ההסתברות של A". פונקציה זו מקיימת שתי תכונות חשובות: ההסתברות של המרחב כולו היא 1; וההסתברות של איחוד זר של מאורעות שווה לסכום ההסתברויות. את התכונה האחרונה הוכחנו במפורש, על-ידי חסימת ההפרש בין שני הסכומים בכל אפסילון חיובי.
קוראים "ההסתברות של A". פונקציה זו מקיימת שתי תכונות חשובות: ההסתברות של המרחב כולו היא 1; וההסתברות של איחוד זר של מאורעות שווה לסכום ההסתברויות. את התכונה האחרונה הוכחנו במפורש, על-ידי חסימת ההפרש בין שני הסכומים בכל אפסילון חיובי.
תרגמנו את עקרון ההכלה וההדחה לשפת ההסתברות.
הגדרנו הסתברות מותנית 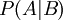 והוכחנו את נוסחת ההסתברות השלמה.
והוכחנו את נוסחת ההסתברות השלמה.
הרצאה רביעית
פתרנו את "בעיית המזכירה המבולבלת" בעזרת עקרון ההכלה וההדחה. הגדרנו מאורעות בלתי תלויים, והוכחנו כמה תכונות שקולות. הגדרנו אי-תלות משותפת של כמה מאורעות, והראינו שאי-תלות משותפת של שלושה מאורעות חזקה ממש מאי-תלות של כל זוג בנפרד.
הרצאה חמישית
הגדרנו משתנה מקרי, כפונקציה (כלשהי) ממרחב הסתברות בדיד (כלשהו) אל המספרים הממשיים. כדי לתאר משתנה מקרי X יש לדעת את ההתפלגות שלו, כלומר הפונקציה המתאימה לכל a את ההסתברות 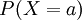 . ראינו שאם מפעילים פונקציה על משתנה מקרי, מתקבל משתנה מקרי חדש, שאפשר לחשב את ההתפלגות שלו מן ההתפלגות של המשתנה הראשון.
. ראינו שאם מפעילים פונקציה על משתנה מקרי, מתקבל משתנה מקרי חדש, שאפשר לחשב את ההתפלגות שלו מן ההתפלגות של המשתנה הראשון.
טיפלנו בהתפלגות משותפת של זוג משתנים מקריים X,Y (המוגדרים על אותו מרחב הסתברות), שהיא הפונקציה המתאימה לכל a,b את ההסתברות 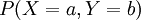 . מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים
. מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד. לסיכום הגדרנו מתי שני משתנים מקריים הם בלתי תלויים: אם לכל a,b מתקיים 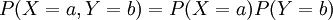 .
.
הרצאה שישית
הגדרנו את התוחלת של משתנה מקרי - מעין ממוצע משוכלל (וגם משוקלל) של הערכים שהמשתנה יכול לקבל. אם הנקודות של המרחב הן בעלות אותה הסתברות ("התפלגות אחידה"), אז התוחלת שווה לממוצע של ערכי המשתנה. התוחלת היא הומוגנית (ממעלה ראשונה) ואדיטיבית: 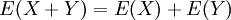 , וזאת לכל שני משתנים מקריים. תכונה חשובה זו מאפשרת לחשב תוחלות באמצעות פירוק המשתנה לסכום של משתנים פשוטים יותר, כגון משתנים מציינים של מאורעות במרחב.
, וזאת לכל שני משתנים מקריים. תכונה חשובה זו מאפשרת לחשב תוחלות באמצעות פירוק המשתנה לסכום של משתנים פשוטים יותר, כגון משתנים מציינים של מאורעות במרחב.
אם X,Y שני משתנים מקריים, X|Y=b (קרי "X בהנתן Y=b") הוא משתנה מקרי, שההתפלגות שלו תלויה בערך של b. אפשר לקצר ולומר ש-X|Y הוא משתנה מקרי, שההתפלגות שלו תלויה ב-Y. למשתנה הזה יש תוחלת, (E(X|Y, שהיא פונקציה של Y. הוכחנו את חוק התוחלת החוזרת 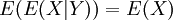 .
.
הרצאה שביעית
כדי לנתח את התוחלת של מכפלות, הגדרנו את השונות המשותפת של שני משתנים: 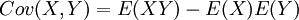 . זוהי פונקציה סימטרית, הומוגנית ואדיטיבית בשני הרכיבים. אם X,Y בלתי תלויים, אז מחוק התוחלת החוזרת נובע ש-
. זוהי פונקציה סימטרית, הומוגנית ואדיטיבית בשני הרכיבים. אם X,Y בלתי תלויים, אז מחוק התוחלת החוזרת נובע ש- 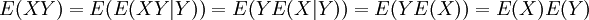 , כלומר, השונות המשותפת שלהם היא אפס. משתנים כאלה נקראים בלתי מתואמים (כל שני משתנים בלתי תלויים הם בלתי מתואמים, אבל ההיפך נכון רק במקרה המיוחד שבו כל אחד משני המשתנים יכול לקבל רק שני ערכים).
, כלומר, השונות המשותפת שלהם היא אפס. משתנים כאלה נקראים בלתי מתואמים (כל שני משתנים בלתי תלויים הם בלתי מתואמים, אבל ההיפך נכון רק במקרה המיוחד שבו כל אחד משני המשתנים יכול לקבל רק שני ערכים).
השונות של משתנה מקרי X מוגדרת כשונות המשותפת שלו עם עצמו: 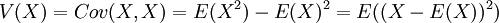 . זהו גודל חיובי, השווה לאפס רק אם המשתנה קבוע (בהסתברות 1). השונות היא פונקציה הומוגנית (מדרגה 2). כאנלוגיה לחוק התוחלת החוזרת, הוכחנו את נוסחת פירוק השונות:
. זהו גודל חיובי, השווה לאפס רק אם המשתנה קבוע (בהסתברות 1). השונות היא פונקציה הומוגנית (מדרגה 2). כאנלוגיה לחוק התוחלת החוזרת, הוכחנו את נוסחת פירוק השונות: 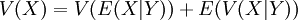 .
.
הרצאה שמינית
למדנו את ההתפלגויות (הבדידות) הקלאסיות:
- ההתפלגות האחידה על המספרים
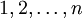 , שאותה מסמנים בסימון
, שאותה מסמנים בסימון ![\ X \sim U[1,n]](/images/math/3/f/b/3fbc5aa1e358398249771be7e3339344.png) . למשל, הערך שמתקבל מזריקת קוביה הוגנת מתפלג
. למשל, הערך שמתקבל מזריקת קוביה הוגנת מתפלג ![\ U[1,6]](/images/math/b/f/1/bf1f0b5d091d01510b6aa53865af36fc.png) , ואילו ספרה אקראית X מקיימת
, ואילו ספרה אקראית X מקיימת ![\ X+1 \sim U[1,10]](/images/math/c/4/1/c41326780473cdbb40d7800b5ebde73f.png) . התוחלת של משתנה כזה היא
. התוחלת של משתנה כזה היא 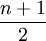 , והשונות
, והשונות 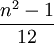 .
. - התפלגות ברנולי:
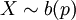 , שבה X מקבל רק את הערכים 0 (בהסתברות q=1-p) או p. התוחלת שווה לפרמטר p, והשונות היא pq. כל משתנה מקרי המקבל רק שני ערכים אפשר להביא (על-ידי העתקה לינארית) לצורה כזו. לדוגמא, אם X מקבל את הערכים אחד ומינוס אחד, אז
, שבה X מקבל רק את הערכים 0 (בהסתברות q=1-p) או p. התוחלת שווה לפרמטר p, והשונות היא pq. כל משתנה מקרי המקבל רק שני ערכים אפשר להביא (על-ידי העתקה לינארית) לצורה כזו. לדוגמא, אם X מקבל את הערכים אחד ומינוס אחד, אז 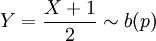 עבור p מתאים.
עבור p מתאים. - התפלגות בינומית:
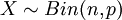 היא ההתפלגות של המשתנה הסופר כמה הצלחות יש בסדרה של n "ניסויי ברנולי" (ניסויים בלתי תלויים, שהסיכוי להצלחה בכל אחד מהם הוא קבוע, p). התוחלת של משתנה כזה היא np, והשונות npq (ההוכחה הקלה ביותר היא דרך משתנים מציינים).
היא ההתפלגות של המשתנה הסופר כמה הצלחות יש בסדרה של n "ניסויי ברנולי" (ניסויים בלתי תלויים, שהסיכוי להצלחה בכל אחד מהם הוא קבוע, p). התוחלת של משתנה כזה היא np, והשונות npq (ההוכחה הקלה ביותר היא דרך משתנים מציינים). - התפלגות פואסון:
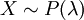 , המוגדרת כך ש-
, המוגדרת כך ש-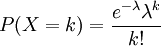 . התוחלת והשונות הן
. התוחלת והשונות הן 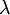 . התפלגות זו מופיעה כקירוב להתפלגות בינומית (אם , ו-n גדול, אז בקירוב טוב
. התפלגות זו מופיעה כקירוב להתפלגות בינומית (אם , ו-n גדול, אז בקירוב טוב 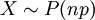 ), וגם בספירת תופעות לאורך זמן. את עניין ספירת התופעות לאורך זמן נסביר כשנלמד את ההתפלגות המעריכית (הרציפה).
), וגם בספירת תופעות לאורך זמן. את עניין ספירת התופעות לאורך זמן נסביר כשנלמד את ההתפלגות המעריכית (הרציפה). - התפלגות גאומטרית:
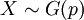 היא ההתפלגות של מספר הניסויים שיש לערוך עד להצלחה ראשונה (בסדרה של ניסויי ברנולי). הערך של משתנה זה אינו חסום, אם כי ההסתברות לערכים גדולים הולכת ודועכת (בקצב מעריכי). ההתפלגות הגאומטרית מיוחדת בתכונת חוסר הזכרון שלה: הידיעה שכבר נכשלו k ניסויים אינה מקרבת (ואינה מרחיקה) את ההצלחה הראשונה שתבוא.
היא ההתפלגות של מספר הניסויים שיש לערוך עד להצלחה ראשונה (בסדרה של ניסויי ברנולי). הערך של משתנה זה אינו חסום, אם כי ההסתברות לערכים גדולים הולכת ודועכת (בקצב מעריכי). ההתפלגות הגאומטרית מיוחדת בתכונת חוסר הזכרון שלה: הידיעה שכבר נכשלו k ניסויים אינה מקרבת (ואינה מרחיקה) את ההצלחה הראשונה שתבוא. - התפלגות "בינומית שלילית": מספר הניסויים שאפשר לבצע (בסדרת ניסויי ברנולי) עד לכשלון ה-k. הפרמטרים הם k וההסתברות הקבועה, p.
- התפלגות היפרגאומטרית: ההתפלגות של מספר הכדורים האדומים שמתקבלים כשמוציאים n כדורים (ללא החזרה!) מכד שבו A כדורים אדומים ו-B כדורים כחולים.
הרצאה תשיעית
בין ההתפלגויות השונות יש קשרים רבים, גם מעבר למובן מאליו (משתנה בינומי מוגדר כסכום של n משתנים מקריים ברנוליים בלתי-תלויים; משתנה "בינומי שלילי" אפשר להגדיר כסכום של משתנים מקריים גאומטריים). למשל:
- אם X,Y משתנים בינומיים בלתי תלויים עם אותו p (אבל n-ים שונים), אז X+Y בינומי (עם אותו p), משום שהוא סופר את כל ההצלחות בסדרה ראשונה ואחר-כך בסדרה שניה של ניסויים.
- אם X,Y משתני פואסון ב"ת, סכומם פואסוני (עם תוחלת השווה לסכום התוחלות, מה שאפשר לתרגם לחישוב הפרמטר, שהוא סכום הפרמטרים של X,Y).
- במקרה הקודם, ההתפלגות של X בהנתן X+Y היא בינומית.
- אם N הוא מספר ההתפרקויות של חלקיקים רדיואקטיביים במבחנה לאורך 25 דקות (משתנה פואסוני), ו-X הוא מספר ההתפרקויות שבהן התוצרים פגעו בלוחית המדידה (תופעה שהסיכוי לה הוא p, כלומר X בהנתן N מתפלג בינומית), אז X הוא משתנה פואסוני.
- אם X,Y משתנים מקריים גאומטריים, אז ההתפלגות של X בהנתן X=Y היא עדיין גאומטרית (הראו כמה קל למצוא את הפרמטר אם העובדה הזו על התפלגות X בהנתן X=Y ידועה!)
דוגמאות חשובות אחרות מתקבלות משאיפה לגבול.
- כאשר X מתפלג בינומית ו-n גדל תוך שהמכפלה np נשארת קבועה, ההתפלגות הולכת ומתקרבת להתפלגות פואסון עם הפרמטר np.
- בהתפלגות היפרגאומטרית, אם מגדילים את A,B תוך שמירה על היחס A:B, התהליך הולך ונעשה דומה לדגימה עם החזרה (משום שכשיש בכד המוני כדורים, ממילא הסיכוי לחזרה על אותו כדור הוא זניח), ואז המשתנה ההיפרגאומטרי נעשה בקירוב בינומי.
הרצאה עשירית
מעבר להתפלגויות הקלאסיות, חשוב לדעת גם לטפל בתופעות שבהן חישוב ישיר הוא מסובך או בלתי אפשרי, כדי לקבל קירוב להתנהגות שלהן. בחנו מקרוב את הדוגמא המפורסמת של "פרדוקס יום ההולדת": הסיכוי שבין 23 אנשים יהיו שניים שנולדו באותו יום בשנה הוא מעט יותר מחצי, למרות ש-23 "הרבה יותר קטן" מ-365. ההסבר הוא בחישוב הסיכוי לכך שאין התנגשויות בבחירה אקראית של ימי ההולדת: מתברר שהסיכוי הזה יורד בקצב קרוב ל- 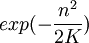 כאשר n הוא מספר האנשים (כאן 23) ו-K גודל המרחב שבו הם בוחרים.
כאשר n הוא מספר האנשים (כאן 23) ו-K גודל המרחב שבו הם בוחרים.
בדרך כלל קל יותר לחשב תוחלות מאשר הסתברויות (במיוחד אם מדובר במשתנה שאפשר לפרק לסכום של משתנים מציינים רבים). גם לגבי ימי הולדת, קל לחשב שתוחלת מספר ההתנגשויות (כלומר, זוגות של אנשים שנולדו באותו יום) היא 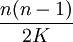 , כך שמספר ההתנגשויות עולה באופן ריבועי עם מספר האנשים, וכאשר n הוא מסדר הגודל של
, כך שמספר ההתנגשויות עולה באופן ריבועי עם מספר האנשים, וכאשר n הוא מסדר הגודל של 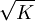 אפשר כבר לצפות להתנגשויות. דיברנו גם על המשתנה של זמן ההמתנה (להתנגשות הראשונה), שגם התוחלת שלו - שאותה לא חישבנו - פרופורציונלית לשורש גודל המרחב.
אפשר כבר לצפות להתנגשויות. דיברנו גם על המשתנה של זמן ההמתנה (להתנגשות הראשונה), שגם התוחלת שלו - שאותה לא חישבנו - פרופורציונלית לשורש גודל המרחב.
את הנימוקים האלה אפשר להפוך על ראשם כדי להעריך את גודל המרחב (כשזה אינו ידוע). אם המחשב בוחר מספרים באקראי ואחרי 979 צעדים מופיע לראשונה אותו מספר בפעם השניה, סביר להעריך שגודל המרחב הוא כ- 979 בריבוע, היינו כמליון.
טכניקת הפירוק לסכום של משתנים מציינים מאפשרת לתאר את המבנה של גרף מקרי (שבו יש n קודקודים, וכל אחת מ-n-מעל-2 הקשתות הפוטנציאליות מתממשת בהסתברות p, באופן בלתי תלוי). נניח ש-p הוא פונקציה של n, וש-n שואף לאינסוף. תארנו בהרצאה מה קורה כאשר p הוא כפולה קבועה של 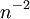 (בשלב זה יש רק מספר סופי של קשתות), או של
(בשלב זה יש רק מספר סופי של קשתות), או של 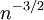 (מספר הקשתות שואף לאינסוף ובגרף יש מסלולים באורך 2, ולא יותר), וכן הלאה. הדרגה של קודקוד מוגדרת כמספר הקשתות שיוצאות ממנו. הדרגה של קודקוד, אם כך, מתפלגת
(מספר הקשתות שואף לאינסוף ובגרף יש מסלולים באורך 2, ולא יותר), וכן הלאה. הדרגה של קודקוד מוגדרת כמספר הקשתות שיוצאות ממנו. הדרגה של קודקוד, אם כך, מתפלגת 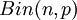 , וכאשר n גדל אפשר לקרב התפלגות זו לפי התפלגות פואסון
, וכאשר n גדל אפשר לקרב התפלגות זו לפי התפלגות פואסון 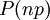 . בפרט, הסיכוי לכך שהקודקוד מבודד הוא בקירוב טוב
. בפרט, הסיכוי לכך שהקודקוד מבודד הוא בקירוב טוב 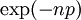 , ולכן תוחלת מספר הקודקודים המבודדים בגרף היא
, ולכן תוחלת מספר הקודקודים המבודדים בגרף היא 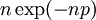 . אם למשל
. אם למשל 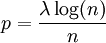 , אז תוחלת מספר הקודקודים המבודדים היא
, אז תוחלת מספר הקודקודים המבודדים היא 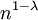 , מה שמסביר מדוע כאשר
, מה שמסביר מדוע כאשר 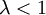 מספר הקודקודים המבודדים שואף לאינסוף, וכאשר
מספר הקודקודים המבודדים שואף לאינסוף, וכאשר 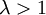 הוא שואף לאפס (והגרף קשיר, למרות שזה דורש כמובן נימוקים נוספים).
הוא שואף לאפס (והגרף קשיר, למרות שזה דורש כמובן נימוקים נוספים).
הרצאה אחת-עשרה
כדי לעבור ממשתנים מקריים בדידים לרציפים, עלינו להכליל את מושג מרחב ההסתברות. בעבר טיפלנו במרחבים סופיים או בני-מניה, ואז הגדרנו את ההסתברות של כל נקודה, וממנה יכולנו לחשב את ההסתברות של כל תת-קבוצה. במעבר למקרה הכללי מתברר שהגישה הזו מוכרחה להכשל: אי אפשר לסכם מספר שאינו בן-מניה של ערכים (ולקוות לתוצאה סופית), וגם אי אפשר להגדיר הסתברות בבת-אחת על כל תת-הקבוצות (אפילו של קטע היחידה).
את הפתרון האקסיומטי מצא קולמוגורוב. ראשית, סיגמא-אלגברה על מרחב 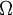 מוגדרת כמשפחה של תת-קבוצות, הכוללת את המרחב כולו כאיבר, וסגורה למשלים וללקיחת איחוד בן-מניה. (סגירות לאיחוד סופי אינה מספיקה, וסגירות לאיחוד כלשהו - לאו דווקא בן-מניה - היא דרישה חזקה מדי המקלקלת את כל הדוגמאות המעניינות). מרחב הסתברות הוא שלשה סדורה, שבה הרכיב הראשון הוא המרחב, השני הוא סיגמא-אלגברה (אבריה נקראים "מאורעות"), והשלישי הוא פונקציית הסתברות, שהיא פונקציה המתאימה מספר חיובי לכל מאורע, ומקיימת שני תנאים: ההסתברות של המרחב כולו היא 1, ואם
מוגדרת כמשפחה של תת-קבוצות, הכוללת את המרחב כולו כאיבר, וסגורה למשלים וללקיחת איחוד בן-מניה. (סגירות לאיחוד סופי אינה מספיקה, וסגירות לאיחוד כלשהו - לאו דווקא בן-מניה - היא דרישה חזקה מדי המקלקלת את כל הדוגמאות המעניינות). מרחב הסתברות הוא שלשה סדורה, שבה הרכיב הראשון הוא המרחב, השני הוא סיגמא-אלגברה (אבריה נקראים "מאורעות"), והשלישי הוא פונקציית הסתברות, שהיא פונקציה המתאימה מספר חיובי לכל מאורע, ומקיימת שני תנאים: ההסתברות של המרחב כולו היא 1, ואם 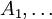 סדרת מאורעות זרים, אז
סדרת מאורעות זרים, אז 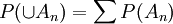 . החסרון בגישה זו הוא שכאשר הסיגמא-אלגברה אינה כוללת את כל תת-הקבוצות (וכך יהיה בדרך כלל), יהיו קבוצות שלא ניתן לדבר על ההסתברות שלהן. מתברר שהשד הזה אינו נורא כל-כך.
. החסרון בגישה זו הוא שכאשר הסיגמא-אלגברה אינה כוללת את כל תת-הקבוצות (וכך יהיה בדרך כלל), יהיו קבוצות שלא ניתן לדבר על ההסתברות שלהן. מתברר שהשד הזה אינו נורא כל-כך.
המרחב החשוב ביותר מבחינתנו הוא הישר הממשי, ולכן אנו ניגשים להגדיר סיגמא-אלגברה מסויימת עליו, הנקראת "הסיגמא-אלגברה של בורל". זוהי הסיגמא-אלגברה הקטנה ביותר הכוללת את כל הקרניים ![\ (-\infty,a]](/images/math/d/2/9/d29fb7922b05cc1874d9fe39cbed89bf.png) . מתברר שהיא כוללת את הקרניים מכל הסוגים, את הקטעים הפתוחים מכל הסוגים, נקודות, סדרות של נקודות, קבוצות כמו
. מתברר שהיא כוללת את הקרניים מכל הסוגים, את הקטעים הפתוחים מכל הסוגים, נקודות, סדרות של נקודות, קבוצות כמו 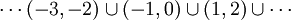 , ועוד ועוד. עם הסיגמא-אלגברה הזו, נוכל לחשב את ההסתברות של מאורעות כמו
, ועוד ועוד. עם הסיגמא-אלגברה הזו, נוכל לחשב את ההסתברות של מאורעות כמו 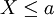 (ולכן גם מאורעות כמו
(ולכן גם מאורעות כמו 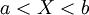 וכדומה) לכל משתנה מקרי X.
וכדומה) לכל משתנה מקרי X.
הרצאה שתים-עשרה
לכל משתנה מקרי אפשר להגדיר את פונקציית ההצטברות 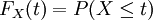 . זוהי פונקציה מונוטונית עולה (במובן החלש), שואפת לאפס במינוס אינסוף ולאחד באינסוף, ורציפה מימין. גם בכיוון ההפוך, כל פונקציה כזו מאפשרת להגדיר משתנה מקרי על-פי ההסתברויות שלו ליפול בקטעים או בקרניים. באופן מעשי, פונקציית ההצטברות נותנת תאור מלא של המשתנה.
. זוהי פונקציה מונוטונית עולה (במובן החלש), שואפת לאפס במינוס אינסוף ולאחד באינסוף, ורציפה מימין. גם בכיוון ההפוך, כל פונקציה כזו מאפשרת להגדיר משתנה מקרי על-פי ההסתברויות שלו ליפול בקטעים או בקרניים. באופן מעשי, פונקציית ההצטברות נותנת תאור מלא של המשתנה.
קבוצת נקודות אי-הרציפות של פונקציית הצטברות היא (לכל היותר) בת מניה. פונקציית ההצטברות של משתנה היא רציפה אם ורק אם ההסתברות למאורעות הנקודתיים X=a היא תמיד אפס.
קבוצת נקודות אי-הגזירות היא תמיד בעלת "מידה אפס", אבל היא עלולה שלא להיות בת-מניה. כאשר הפונקציה גזירה, הנגזרת שלה היא פונקציית צפיפות: פונקציה חיובית שהאינטגרל הכולל שלה הוא 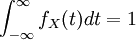 . בכיוון ההפוך, פונקציית צפיפות מגדירה פונקציית הצטברות לפי הנוסחה
. בכיוון ההפוך, פונקציית צפיפות מגדירה פונקציית הצטברות לפי הנוסחה 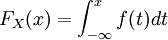 .
.
פונקציית הצפיפות מאפשרת לחשב בקלות את התוחלת של משתנה מקרי רציף: 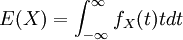 . באופן כללי יותר, לכל פונקציה (מדידה) g התוחלת של המשתנה המקרי
. באופן כללי יותר, לכל פונקציה (מדידה) g התוחלת של המשתנה המקרי 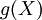 היא
היא 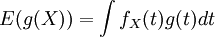 .
.
השונות מוגדרת כרגיל, לפי 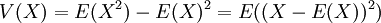 .
.
הרצאה שלוש-עשרה
דוגמאות להתפלגויות רציפות חשובות: (1) ההתפלגות האחידה, שבה הצפיפות של כל הנקודות בקטע (a,b) היא 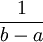 .
.
(2) ההתפלגות המעריכית, עבור פרמטר חיובי 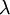 , שבה פונקציית הצפיפות היא
, שבה פונקציית הצפיפות היא 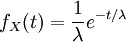 . זוהי ההתפלגות הרציפה היחידה שאין לה זכרון: למשתנה מעריכי X יש אותה התפלגות כמו למשתנה X-a בהנתן X>a.
. זוהי ההתפלגות הרציפה היחידה שאין לה זכרון: למשתנה מעריכי X יש אותה התפלגות כמו למשתנה X-a בהנתן X>a.
תרגיל. המינימום של כמה משתנים מעריכיים בלתי תלויים מתפלג מעריכית.
הרצאה ארבע-עשרה
במקרה הבדיד, את ההתפלגות של משתנה יחיד מתארים בעזרת רשימת הסתברויות, ואת ההתפלגות המשותפת של זוג משתנים בעזרת טבלה דו-ממדית. בדומה לזה, במקרה הרציף מתארים את ההתפלגות של משתנה יחיד באמצעות פונקציית צפיפות (חד-ממדית), ואת ההתפלגות המשותפת של זוג משתנים X,Y באמצעות פונקציית צפיפות דו-ממדית שתכונתה היא 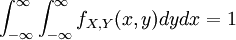 .
.
התפלגות זוג המשתנים מוגדרת לפי הנוסחה 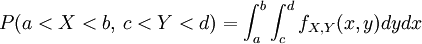 .
.
מן ההתפלגות המשותפת אפשר לשחזר את ההתפלגות של כל משתנה בנפרד: 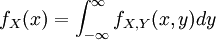 , ובדומה לזה עבור Y. התפלגויות אלו נקראות צפיפות שולית. אומרים שהמשתנים בלתי-תלויים אם הצפיפות המשותפת שלהם היא מכפלת שתי הצפיפויות השוליות.
, ובדומה לזה עבור Y. התפלגויות אלו נקראות צפיפות שולית. אומרים שהמשתנים בלתי-תלויים אם הצפיפות המשותפת שלהם היא מכפלת שתי הצפיפויות השוליות.
אם נתונה הצפיפות של משתנה X, אפשר לעבור ממנה לצפיפות של 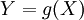 לפי החוק
לפי החוק 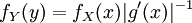 , כאשר
, כאשר 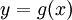 . בדומה לזה אם נתונה הצפיפות של זוג משתנים X,Y, אפשר לעבור ממנה לצפיפות המשותפת של הזוג
. בדומה לזה אם נתונה הצפיפות של זוג משתנים X,Y, אפשר לעבור ממנה לצפיפות המשותפת של הזוג 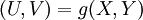 על-ידי חילוק ביעקוביאן של g, שהוא הדטרמיננטה של מטריצת הנגזרות החלקיות של U,V לפי X ולפי Y.
על-ידי חילוק ביעקוביאן של g, שהוא הדטרמיננטה של מטריצת הנגזרות החלקיות של U,V לפי X ולפי Y.
הרצאה חמש-עשרה
בעזרת הנוסחה לטרנספורמציה של זוג משתנים ראינו ש-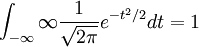 , וזה מאפשר להגדיר את המשתנה שצפיפותו
, וזה מאפשר להגדיר את המשתנה שצפיפותו 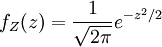 , ולקרוא לו משתנה נורמלי סטנדרטי,
, ולקרוא לו משתנה נורמלי סטנדרטי, 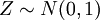 . להתפלגות של
. להתפלגות של 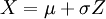 קוראים התפלגות נורמלית, ומסמנים
קוראים התפלגות נורמלית, ומסמנים 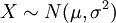
למשפחת ההתפלגויות הנורמליות תכונות מיוחדות רבות. למשל, כל צירוף לינארי של משתנים נורמליים בלתי תלויים הוא נורמלי.
הגדרנו בעזרת ההתפלגות הנורמלית כמה התפלגויות חשובות נוספות, שנפגוש שוב בפרק הסטטיסטי: התפלגות חי-בריבוע, התפלגות t, התפלגות F.
הרצאה שש-עשרה
הוכחנו שני חסמים אוניברסליים על התפלגויות: חסם מרקוב -- לכל משתנה מקרי חיובי X מתקיים 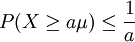 לכל a, כאשר
לכל a, כאשר 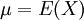 . חסם צ'ביצ'ב -- לכל משתנה מקרי X מתקיים
. חסם צ'ביצ'ב -- לכל משתנה מקרי X מתקיים 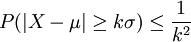 , כאשר ו-
, כאשר ו- 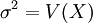 .
.
המומנטים של משתנה מקרי X הם התוחלות 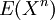 . אפשר לאסוף את כל המומנטים כמקדמים של טור חזקות, ולקבל את הפונקציה יוצרת המומנטים של X,
. אפשר לאסוף את כל המומנטים כמקדמים של טור חזקות, ולקבל את הפונקציה יוצרת המומנטים של X, 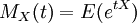 . לדוגמא, חישבנו שהפונקציה יוצרת המומנטים של ההתפלגות המעריכית היא
. לדוגמא, חישבנו שהפונקציה יוצרת המומנטים של ההתפלגות המעריכית היא 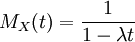 , וראינו שאפשר להסיק מכאן את כל המומנטים,
, וראינו שאפשר להסיק מכאן את כל המומנטים, 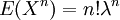 .
.
להתפלגות הנורמלית הסטנדרטית יש פונקציה יוצרת מומנטים 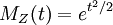 . גם כאן אפשר לקבל את המומנטים בקלות:
. גם כאן אפשר לקבל את המומנטים בקלות: 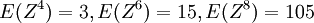 .
.
הרצאה שבע-עשרה
הגדרנו כמה אופנים שבהם יכולה סדרה של משתנים מקריים להתכנס למשתנה מקרי. בפרט אנחנו מעוניינים בהתכנסות של סדרת הממוצעים אל התוחלת (שהיא קבוע, כמובן). החוק החלש של המספרים הגדולים קובע שהממוצעים מתכנסים בהסתברות אל התוחלת (כלומר, ההסתברות לכך שהממוצע יהיה קרוב כדי אפסילון לתוחלת, שואפת ל-1). הוכחנו חוק זה בעזרת אי-שוויון צ'ביצ'ב.
החוק החזק של המספרים הגדולים (שאותו לא הוכחנו) קובע שבהסתברות 1, סדרת הממוצעים מתכנסת אל התוחלת.
משפט הגבול המרכזי עוסק בהפרש בין הממוצע לתוחלת, כשהוא מנורמל כך שהשונות שלו תהיה 1. המשפט מראה שההפרשים "מתכנסים בהתפלגות" אל ההתפלגות הנורמלית, כלומר, פונקציות ההתפלגות מתכנסות נקודתית אל הפונקציה הנורמלית. את המשפט הוכחנו (עד כדי למה ב"אנליזת פורייה", שלא הוכחנו) על-ידי חישוב הגבול של פונקציות יוצרות מומנטים.
הרצאה שמונה-עשרה
עברנו לסטטיסטיקה: הסקת ערכים ומסקנות על האוכלוסיה מתוך מדגם. השלב הראשון הוא אמידה של פמרטרים (כמו התוחלת, השונות, או כל פרמטר אחר המייחד התפלגות) לפי ערכים של מדגם. הגדרנו מהו אומד חסר הטיה, והצגנו את שיטת אומד הנראות המקסימלית. ראינו שאומד הנראות המקסימלית אינו בהכרח חסר הטיה. הדגמנו את השיטות על ססטיסטיי הסדר של מדגם מתוך התפלגות אחידה.
הרצאה תשע-עשרה
דיברנו על רווחי סמך, שהם רווחים שקצותיהם תלויים במדגם, ועבורם הסיכוי לכלול את ערך הפרמטר הוא מספר קבוע מראש (למשל 95% - רמת המובהקות של רווח הסמך).
בפרט בנינו נוסחאות לרווחי סמך עבור התוחלת בהתפלגות נורמלית, ראשית כאשר השונות ידועה, ושנית כאשר ההתפלגות אינה ידועה.
בדומה לזה בנינו רווחי סמך לשונות עצמה, כאשר אומדים אותה משונות המדגם.
הרצאה עשרים
דנו בבדיקת השערות: בדיקה של השערות (בעיקר נקודתיות) על פרמטרים של האוכלוסיה. הצגנו את השערת האפס וההשערה האלטרנטיבית, ודיברנו על שני סוגי השגיאות האפשריים.
תארנו בהרחבה את השלבים העיקריים בתהליך: הרקע התאורטי, הרקע הסטטיסטי, ביצוע הניסוי והפרשנות.
בסופו של דבר, בדיקת השערות מתמצה בבדיקה האם הערך שנטען לפרמטר נופל בתוך רווח סמך מתאים.
הרצאה עשרים ואחת
ראינו כיצד לבצע בדיקת השערות (חד-צדדית ודו-צדדית) על התוחלת בהתפלגות נורמלית (עם שונות ידועה או לא ידועה); על השונות; על הפרש תוחלות (תחת הנחות שונות על שתי השונויות); ועל פרופורציה.
הרצאה עשרים ושתיים
הגדרנו מהו תהליך מרקוב וראינו שמטריצת המעבר מאפשרת, על-ידי העלאה בחזקה, לחשב את הסתברויות המעבר לכל מספר של צעדים. הראינו שלמטריצה זו תמיד יש וקטור עצמי השייך לערך העצמי 1, ווקטור זה הוא ההתפלגות הסטציונרית המתארת את התנהגות התהליך "בטווח הארוך".
הרצאה עשרים ושלוש
ראינו שאפשר להציג תהליך מרקוב באופן גרפי, ונעזרנו בכך כדי לחשב את הסתברויות ההגעה למצבים סופגים ואת תוחלת הזמן עד להתרחשות זו. ראינו שבעזרת ההתפלגות הסטציונרית אפשר להפוך את ציר הזמן, ולחשב את ההסתברות שהיינו במקום מסויים אם אנחנו נמצאים כעת במקום אחר.
הרצאה עשרים וארבע
פתרנו שאלות נוספות בעזרת תהליכי מרקוב; למשל, מה הסיכוי שתהליך מסויים יימשך מספר זוגי של צעדים.
הרצאה עשרים וחמש
תהליך מרקוב הוא מטבעו חסר זכרון. הראינו שאפשר לבצע "הרחבת זכרון" על ידי הגדלת מספר המצבים, באופן שיאפשר מעקב מדוייק יותר אחרי התנהגות התהליך.